



TINTIN Project
TINTIN Project
Are there cross-cultural patterns in the visual languages used in comics of the world? Do those patterns connect to the spoken languages of the comic creators? Do people’s languages or comic reading experience influence how they comprehend comics?
We are addressing these questions in the TINTIN Project, officially known as “Visual narratives as a window into language and cognition.” The TINTIN Project is funded by a €1.5 Million Starting Grant from the European Research Council.
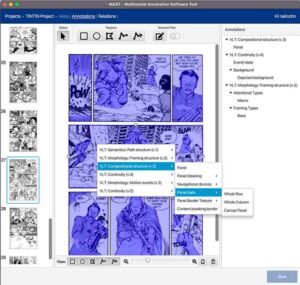
We have created the Multimodal Annotation Software Tool (MAST) to enable the analysis of visual and multimodal documents. With it, we have created the TINTIN Corpus consisting of 1,030 annotated comics from 144 countries and territories.
The TINTIN Corpus includes data about panels, characters, layout, framing, backgrounds, continuity, compositional structure, emotion, motion events, perspective taking, gender, conventionalization of panels, color, and various other features of the visual languages used in comics.
We are currently in the later stages of data collection. Both MAST and the TINTIN corpus will be made open to researchers.

The TINTIN Project is a follow up from the Visual Language Research Corpus which analyzed cross-cultural variation in comics from Asia, Europe, and the United States, and is analyzed in the book The Patterns of Comics.
Want to read more about the TINTIN Project? Check out our TINTIN Project related blog posts with periodic updates and insights.
Team Members
Our current research team consists of several core staff and various collaborators around the world help find and analyze comics for our corpus and conduct experiments. We welcome additional collaborations, so if you are interested in working with us on this project, please inquire with Neil Cohn for details.
At Tilburg University, we collaborate with faculty members Joost Schilperoord and Myrthe Faber.
Bruno Cardoso was a postdoctoral fellow who designed and programmed the Multimodal Annotation Software Tool (MAST).
Ana Krajinović was a postdoctoral fellow analyzing the TINTIN Corpus for its typological properties.
Bien Klomberg and Irmak Hacımusaoğlu were PhD students analyzing cross-cultural visual language typology and conducting experiments.
Sharitha van der Gouw was a research associate assisting in annotation and research.
Fernando Casanova (University of Murcia, Spain) was a visiting PhD student who studies interjections in cross-cultural comics.
Maki Miyamoto (Japan Advanced Institute of Science and Technology) is a visiting PhD student who studies ideophones in cross-cultural comics.
Harshit Singh (Denmark) and Ahmet Sefa Konuş (Turkey) are visiting Erasmus+ interns.
Student contributors
Additional assistance has come from Fred Atilla, Anneliek Bastiaanssen, Puck van Bavel, Nikki Born, Freek van den Broek, Iris Degen, Klava Fadeeva, Marleen Gerritsen, Ange Hamers, Tim Hankart, Kylian van Herwaarden, Kea Kimmel, Matea Mikelin, Daphne Mathijsen, Hester Muller, Lisa Prévost, Annelou Schleckens, Aleksandra Siedlecka, Abe Simons, Yasmilla Stolvoort, Filip van der Vegt, Janessa Vleghert, Celine Wetzler, and others.
External Collaborators and contributers
Nanne van Noord (University of Amsterdam) is an Assistant Professor of Visual Culture and Multimedia and is contributing computer vision analyses to the TINTIN Project.
Kazuki Sekine (Waseda University) is an Associate Professor and is contributing annotations of gestures to the TINTIN Corpus.
Various scholars have helped with gathering the comics for the TINTIN Corpus:
- Tomas Gaete Altamirano (Independent researcher)
- Tahereh Eghbal (Iran)
- Heinz Insu Fenkl (State University of New York, New Paltz)
- Leandro Kruszielski (Universidade Federal do Paraná, Brazil)
- Fajar Laksana (Independent researcher)
- Anna Marta Marini (Instituto Franklin-UAH)
- Marianna Pagkratidou (TU Dublin University)
- Michael Ranta (Lund University)
- Kazuki Sekine (Waseda University, Japan)
- Gaurav Singh (Independent researcher)
- Dušan Stamenković (University of Niš, Serbia)
- Sri Suryani (Independent Researcher)
- Michał Szawerna (University of Wroclaw)
- Eszter Szép (Independent researcher and curator)
- The Thai Comics Archives (Nicolas Verstappen, Chulalongkorn University)
- Miloš Tasić (University of Niš, Serbia)
- Yen Na Yum (Hong Kong Institute of Education)
Contributors
Our TINTIN Corpus consists of 1,030 comics from 144 countries and territories. This multicultural research corpus has benefited from contributions and donations from several creators and companies:
- Abrafaxe (Mosaik)
- AdiFitri
- Akvile Magicdust
- Alastair Laird
- Anje Wicki
- Anna Tsocheva
- Associazione Culturale Altrinformazione
- Awali Comics
- AzCorp Entertainment (Mobile App)
- Barbara Stok
- Becco Giallo
- Bella Dalton-Fenkl
- Beyond Reality Media
- Bjarni Hinriksson
- BK Pena
- Bullseye Press
- Carla Berrocal
- Casper Sand Christiansen
- Christer Bøgh Andersen
- Comics Factory (Yulia Magera)
- Cotton Star
- Daniel Atanasov
- Deena Mohamed
- Dhaka Comics
- Diabolik
- Earth’s End Publishing
- Emiliyan & Stanimir Valev
- Emmi Valve
- Egmont
- FanHunter
- Floris Oudshoorn
- Frank Madsen (Eudor)
- Galago
- Gerda Jord
- Gestalt Comics
- Gustavo Vargas Tataje
- Irish Comics
- Isuri
- Jacob Thybo
- Janne Toriseva (IG)
- Jogjakarta Library Center
- Julien Cachemaille
- Juni Ba
- KompasGid
- Luke Molver
- Maple Comics
- Marko Turunen
- Marmara Çizgi
- Marissa Delbressine
- Marcel Ruijters
- Martin Ernstsen
- Matti Hagelberg
- Mighty Punch Studios (Facebook)
- Mirror Comics
- Panjebar Semangat
- Patrick Steptoe
- Peda Entertainment
- Pentti Otsamo
- Peter Snejbjerg
- Petri Hiltunen
- Peynama
- PRUVE Comics (Facebook, YouTube)
- Rebellion/2000 AD
- Roel Venderbosch
- Ronald “Radical” Diaz (IG)
- Ross Murray
- Sachi Ediriweera
- Samuli Lintula
- Self Made Hero
- Shaunak Samvatsar
- Shujaaz Inc
- SILENT MANGA AUDITION®
- Tatiana Goldberg
- TCZ Studio
- Tero Mielonen
- Timarit.is (Bjarni Hinriksson)
- Tiitu Takalo
- Tommi Musturi
- Toni Timonen
- Total Vision
- Two Gargoyles Comics
- Ville Ranta
- Ville Tietäväinen
- Wilbert van der Steen
TINTIN Project Publications
Theoretical/Review/Experimental
- Neil Cohn, Irmak Hacımusaoğlu, Bien Klomberg, and Ana Krajinović. 2024. TINTIN Project Documentation: Visual Language Theory Annotation Guides. Tilburg University. Visual Language Lab Resources. Download pdf (175 pages, 55MB)
- Klomberg, Bien, Joost Schilperoord, and Neil Cohn. 2024. Constructing Domains in Visual Narratives: Structural Patterns of Incongruity Resolution. Journal of Comparative Literature and Aesthetics: Advances in Neuroaesthetics. 47(3): 37-55 (Pdf)
- Hacımusaoğlu, Irmak and Neil Cohn. 2023. The meaning of motion lines?: A review of theoretical and empirical research on static depiction of motion. Cognitive Science. 47 (11):e13377 (Open online)
- Klomberg, Bien, Irmak Hacımusaoğlu, Lenneke Lichtenberg, Joost Schilperoord, and Neil Cohn. 2023. Continuity, Co-reference, and Inference in Visual Sequencing. Glossa: a journal of general linguistics 8(1). (Read online)
- Klomberg, Bien, Irmak Hacımusaoğlu, Cas Coopmans, and Neil Cohn. Sequential meaning-making in language and visual narratives. In Proceedings of the Annual Meeting of the Cognitive Science Society, vol. 43, no. 43. 2021.(Read online)

TINTIN Corpus
- Cohn, Neil, Andrew T. Hendrickson, Bruno Cardoso, Bien Klomberg, Irmak Hacımusaoğlu, Ana Krajinović, Sharitha van der Gouw, Fred Atilla, Abe Simons, Tim Hankart, Nanne van Noord, Sam Titarsolej, Fernando Casanova Martínez, Tomás Gaete Altamirano, Marianna Pagkratidou, Michał Szawerna, Nicolas Verstappen, Heinz Insu Fenkl, Leandro Kruszielski, Anna Marta Marini, Gaurav Singh, Dušan Stamenković, Miloš Tasić, and Yen Na Yum. 2026. The properties of panels in global comics: Frequency and size of 76K panels in 1,030 comics from 144 countries. Language Resources and Evaluation 60 (47):1-25. (Read online)
- Krajinović, Ana, Hacımusaoğlu, Irmak, & Neil Cohn. 2026. Underspecification and communicative efficiency of visual affixes of motion in comics. In Proceedings of the 48th Annual Meeting of the Cognitive Science Society. Volume 48, 2026 (coming soon)
- Cohn, Neil, Joost Schilperoord, and Bruno Cardoso. 2026. Information, iconicity, and Zipf’s law of abbreviation in visual languages of global comics. Language and Cognition 18 (e12):1-15. (Read online)
- Cohn, Neil, Filip van der Vegt, Fred Atilla, and Bruno Cardoso. 2025. Going with the comics flow: A theoretical and empirical basis for flow in comics. Journal of Graphic Novels and Comics: 1-18. (Journal website, Open PDF)
- Hacımusaoğlu, Irmak, Bruno Cardoso, and Neil Cohn. 2025. Whoosh! visual depictions of direction, speed, and temporality: a corpus analysis of motion events in global comics. Multimodal Communication (Read online)
- Krajinović, Ana, Irmak Hacımusaoğlu, Bruno Cardoso, and Neil Cohn. 2025. Mark the unexpected! Animacy preference and goal-directed movement in visual language. Cognitive Science 49 (5):e70067 (Read online)
- Cohn, Neil, Fred Atilla, Lenneke Lichtenberg, and Bruno Cardoso. 2025. The influence of writing systems on comics layouts. Cognition 260 (106136):1-8. (Read online)
- Titarsolej, Sam, Neil Cohn, and Nanne van Noord. 2024. Drawing Insights: Sequential Representation Learning in Comics. In 35th British Machine Vision Conference 2024, (BMVC) 2024, Glasgow, UK, November 25-28, 2024. Glasgow, UK: BMVA. (Read online)
- Atilla, Fred, Bien Klomberg, Bruno Cardoso, Neil Cohn. 2023. Background Check: Cross-Cultural Differences in the Spatial Context of Comic Scenes. Multimodal Communication. (Read Online)
- Cardoso, Bruno and Neil Cohn. 2022. The Multimodal Annotation Software Tool (MAST). In Proceedings of the 13th Language Resources and Evaluation Conference, 6822‑6828. Marseille, France: European Language Resources Association.
Experimental
- Hacımusaoğlu, Irmak and Neil Cohn. Are we moving too fast?: Representation of speed in static images. Journal ofCognition. 8(1):1, 1-18 (Read online)
- Klomberg, Bien, Klavdiia Fadeeva, Joost Schilperoord, and Neil Cohn. 2025. Processing incongruity for mental events in comics: Contours of character inferences. Metaphor and Symbol. 40(1): 51-75 (Read online)
Visual Language Research Corpus (VLRC)
- Cohn, Neil, Bruno Cardoso, Bien Klomberg, and Irmak Hacımusaoğlu. 2023. The Visual Language Research Corpus (VLRC): An annotated corpus of comics from Asia, Europe, and the United States. Language Resources and Evaluation. (Read online)
- Hacımusaoğlu, Irmak, Bien Klomberg, and Neil Cohn. 2023. Navigating Meaning in the Spatial Layouts of Comics: A cross-cultural corpus analysis. Visual Cognition. (Read online)
- Cohn, Neil, Irmak Hacımusaoğlu, and Bien Klomberg. 2023. The framing of subjectivity: Point-of-view in a cross-cultural analysis of comics. Journal of Graphic Novels and Comics. 14 (3):336-350 (Read online)
- Hacımusaoğlu, Irmak and Neil Cohn. 2022. Linguistic Typology of Motion Events in Visual Narratives. Cognitive Semiotics. 1-26. (Read online)
- Klomberg, Bien, Irmak Hacımusaoğlu, and Neil Cohn. 2022. Running through the Who, Where, and When: A cross-cultural analysis of situational changes in comics. Discourse Processes. (Read online)
Popular writing
- Krajinović, Ana. 2024. Research on Comics Reveals How We Perceive What Is Alive. Medium. (Read online)
- Klomberg, Bien. 2023. Beeldtaal. VakTaal: Tijdschrift van de Landelijke Vereniging van Neerlandici. 36(2/3), 32-33.
- Hacımusaoğlu, Irmak. 2023. Visual language? What even is that? Visual Language Theory and motion in comics. The Cognizer. (Read online)
- Hacımusaoğlu, Irmak. 2023. Görsel Dil mi, O da Ne?: Görsel Dil Teorisi ve Çizgi Romanlarda Hareket. Medium. (Read online)
This project has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 850975).
